Hardly anyone understands fingerprint security
Yesterday there was a post on slashdot about MasterCard adding fingerprint scanners to credit cards. Predictably, to me anyway, the post generated a host of dismissive comments saying it's a stupid idea... and in the process revealing that they do not understand biometric security. I replied at length, and, as I always do, thought "I really need to write a blog post to explain this, so in the future I can just post a link rather than typing a ton."
This is that blog post.
Claim: Fingerprint authentication is serious James Bond shizzle and it's totally secure.
No. No, it's not. See below.
Claim: Fingerprint authentication is insecure because you only have ten fingers, and when you've used them all you have no more new "passwords".
This is wrong, because it assumes that fingerprints (or other biometrics) are just a slightly different sort of password. They're not. Biometric authenticators are nothing at all like passwords; the security model is completely different. To understand how and why, we first need to understand the password security model.
Why are passwords secure? Passwords are secure when the attacker doesn't know them. That seems simple and obvious, but subtleties arise when you think about how an attacker might get them. There are two primary ways: stealing copies, and repeated guessing, also known as a "brute force search". These interact — in some cases the attacker can steal part and guess the rest — and there are many methods of optimizing both, but it all boils down to getting a copy, or guessing.
Suppose the attacker has obtained a copy of your password, without your knowledge. Your security is compromised, but now the attacker has a choice. He can change your password, lock you out of your own account/device and use it for his own purposes, or he can leave your password and make covert use of your account. In many cases, the attacker opts for the latter approach because the former is too noticeable and the account/device often quickly gets shut down. Or suppose the attacker has obtained a copy of your password but hasn't gotten around to using it yet. In either case, changing your password shuts off the attacker's access, closing the window of vulnerability.
There's another reason to change your password from time to time, to protect it against compromise by guessing. Depending on how the system is built, what information the attacker has to start with and the attacker's resources, the attacker will be able to make guesses at some rate. If you change your password before the attacker can guess your password, the attacker has to start over. Another way to look at it is that as the attacker guesses, he gains knowledge about your password, by knowing what it is not. When you change your password, that knowledge is invalidated.
In a nutshell: Password security derives from password secrecy, and you remove whatever knowledge the attacker has when you change it (assuming you don't just change a character or two). Another way of looking at it is that password secrecy erodes over time, and rotation restores it.
But your fingerprints are not secret. You leave them on almost everything you touch. From a security perspective the only reasonable way to think about biometrics is that they are public information. We have to assume the attacker already has your fingerprints. In the case of smartphone or a credit card, odds are good that there are nice fingerprints on the device itself.
The purpose of password rotation is to restore eroding secrecy, but fingerprints aren't secret to begin with, so rotating would serve no purpose. It's completely irrelevant that you only have a limited number of fingerprints. Also, if fingerprint authentication security relies on the secrecy of non-secret information, it's broken. So either biometrics are just insecure or the security comes from something other than secrecy.
Claim: Fingerprints aren't passwords, they're usernames!
People who sort of recognize that fingerprints really aren't like passwords often fall into this trap, aided by some widely-shared blog posts like this one. This idea that fingerprints are identifiers seems to be buttressed by the fact that the criminal justice system often uses fingerprints to identify people (except it really doesn't). So if fingerprints don't seem to fit the model of passwords, maybe they're usernames?
No. They're not. Biometrics are lousy identifiers. Good identifiers should have uniqueness guarantees, biometrics don't. Good identifiers should always either match or not match, biometric matching is fuzzy, every match is a judgement call. If your database of potential identities is at all large this fuzziness invokes an interesting little statistical fact known as the Birthday Paradox.
In the context of birthdays, the paradox goes like this: Suppose you're at a party with 30 people. What are the odds that two of them have the same birthday? Most people guess that the odds are low, since there are many more days in the year than people. Actually, assuming uniform distribution of birthdays (no days more likely than others), there is a 71% chance that at least one same-birthday pair exists. If you can get someone to give you an even-odds bet at such a party (and you know the other person doesn't have knowledge of the attendees birthdays), take it. You may lose (29% chance) but over the course of a few such parties you're guaranteed to come out ahead.
Why is the probability of a match so high? While there are only 30 people at the party, there are 30 ⋅ 29 = 870 pairs of people, and still only 366 days. That's a very handwavy justification; see the Wikipedia article for the math if you're really interested.
What does this have to do with biometrics? Well, birthdays are one way of classifying people into sets, and biometrics are another.
If you think about the space of all possible fingerprints then my right index finger is a point in that space. There may in fact be no other person with a finger occupying that same point. But measurement of fingerprints is imprecise, so a fingerprint matcher actually accepts any point sufficiently close to my finger as being my finger. How close is close enough?
It's a tradeoff. A very tight bound means that very often when I put my finger on the scanner, the matcher will say it's not close enough to mine to be me. This is a false reject and the rate at which is happens is called, sensibly enough, the false reject rate, or FRR. A very loose bound means that often when someone else puts their finger on the scanner, the matcher will say it's close enough to be me. This is a false accept, and the rate is the FAR. Tuning the bound allows trading FAR for FRR and vice versa.
So, for any given bound, within the space of all fingerprints there is a set of people with prints who match me, and I them, though not every time because remember that the scanning process is imprecise. It's not quite the same as the very crisp categorization of birthdays, but it's close enough, and it's definitely the case that the Birthday Paradox applies.
Of course, fingerprint matchers distinguish much more finely than birthday categorization. Common systems have FAR values of 1:50,000 or less, whereas birthdays are 1:365.2425. But people want to create databases with far larger numbers than attend a party. If you have a database with 1,000 people in it, you have 999,000 pairs of people in your database and that 1:50,000 FAR looks pretty skimpy. Bump this up to databases with millions, or hundreds of millions, or billions of people and the FAR would have to be impossibly low to reliably and uniquely identify every one of them.
With usernames we address this problem by enforcing uniqueness. If you try to create an account with an already-taken username, the system demands that you pick a different username. We can't do that with biometrics.
So biometrics in general, and fingerprints in particular, are not good usernames.
Claim: Fingerprints are bad usernames (not unique, fuzzy) and bad passwords (not secrets), so fingerprints authentication is useless.
This is also wrong. This view implicitly assumes that the only possible authentication security model is the password model, which relies on secrecy. It's not. The reason passwords have to be secret is because if the attacker knows the password, the attacker can present the password to "prove" his identity. Biometrics are different. Merely knowing what your fingerprint looks like does not enable the attacker to present it to the system. More is required... and that more is the source of security provided by biometrics.
So... just how hard is it for an attacker to fake your fingerprint? It depends. On a lot of things. Can the attacker bypass the scanner and provide a digital image of your fingerprint directly to the matcher? If so, then the fingerprint is a password, and we've already seen that fingerprints are not secret. But, systems can and do implement countermeasures to prevent this attack, such as having the scanner cryptographically sign the images it sends and having the matcher reject any that don't have the correct signature. Plus, this sort of attack requires hardware hacking that is beyond the skill level of many potential attackers (I'll come back to this point).
If the attacker can't inject digital data directly, that means he must somehow create a fake fingerprint and get the scanner to accept it as a real one. Scanners implement some "liveness detection" countermeasures that attempt to make this difficult, with varying degrees of success. (Liveness detection also hopes to defeat the more gruesome stolen-finger attack). Again, though, creating a fake finger that will work takes some skill and some effort which is beyond the capability of many attackers. In addition, getting it right often requires some trial and error, especially if the attacker doesn't actually know the fingerprint to use, but only has a set of prints lifted from surfaces you touched, some of which may not be yours, and some of which may be yours, but not the right finger.
In some contexts, stronger countermeasures can be implemented. For example, military access control systems that use biometric authentication often have an armed guard who is trained to look for finger fakery. This makes using a fake (or stolen) finger harder and increases the consequences of failure. Luckily for him, the systems Mr. Bond encounters always seem to be unattended, or attended by an easily-subdued guard.
Claim: Fingerprint authentication isn't useless in all circumstances, but the way it has to be implemented in a smartphone or a credit card or a personal computer makes it useless.
Fingerprint security depends not on secrecy but on the difficulty of presenting a known fingerprint that is not the attacker's own. How hard that is depends on the details of the system. Whether that is hard enough depends on the attacker: motivation, tolerance for risk and ability. What sorts of attackers are interested in defeating authentication is determined by how much value they find in defeating it. If the fingerprint auth is the only thing protecting a billion dollars, or nuclear weapons, or any other very high-value target (to some attacker), then motivation, risk tolerance and ability will all be high. If it's protecting my contact list... not so much. Especially since if the attacker can drum up some plausible reason for needing to know my contact list, he can just ask me (this is called social engineering).
So, how valuable is a credit card? A few thousand dollars at the outside, and there are non-trivial risks and difficulties in getting that money and getting away with it. There are certainly people willing to brave the risks for the rewards, but they tend not to be people with high levels of technical skill or a taste for the tedious, detailed work required to lift good prints and make good fake fingers. Those sorts of people can generally acquire thousands of dollars in risk-free, socially-approved ways. Some choose not to, but they're very unusual.
Also, you have to consider what the fingerprint authentication is replacing, because this is an augmentation of an existing, well-understood and reasonably well-functioning system. What is it replacing? Essentially... nothing. The US does not use chip-and-PIN so the only form of user authentication we have now is signature. Which is nothing. No one checks it, and no one knows how to check it if they want to, except at the crudest level. So in the context of credit cards, fingerprint authentication is an unambiguous improvement, as long as the existing backend-based risk management systems are retained.
What about smartphones? Their value varies tremendously. At the low end, there is the resale value of the device itself. At the high end, they may contain immensely valuable secrets. Donald Trump's Twitter password can move stock markets. Larry Page's email likely contains the details of multi-million dollar acquisition proposals. Somewhere in between the low and high end, attackers are willing and able to hack hardware and fake fingers.
But, again, you have to consider the alternative. At the low end, the majority of smartphones without fingerprint scanners have no password, and so no security at all, other than some degree of care to retain physical possession. People don't password their phones because it's inconvenient to enter a password many times per day. Others are willing to put up with a little inconvenience in the name of security so they use a password, but choose a very weak one, easily guessed or shoulder-surfed. Or if they choose a middling password (basically no one chooses a good one for their phone), they set the lockscreen timeouts to be very high so that they don't have to enter it often — very convenient for the attacker who finds/steals the device.
For the vast majority of smartphone users, then, a fingerprint is an unambiguous improvement in the security of their device.
Bottom line:
Biometric authentication is not perfect, nor is it useless. It works differently from password authentication, has a different security model with different tradeoffs. Whether it's workable for a particular context depends on the details; you have to understand the security model and analyze the situation in detail considering risks, expected sorts of attacker, and alternatives. And it's actually pretty good for most smartphone users and most credit card holders.
Friday, April 21, 2017
Wednesday, February 24, 2016
Web security
People don't understand web security, even many who should
Yesterday I posted a Google+ poll about what is and isn't safe on an unknown Wifi access point, and 93% of the 30 responses were wrong, in spite of the fact that many of the people who follow me are technical and even have a security bent. This did not surprise me.
The question was "You're connected to some random public Wifi hotspot. You know nothing about who owns it or why they make it public (the SSID says it's STARBUCKS and there is a nearby Starbucks, but who knows?), but it gives you a functional Internet connection. Which of the following is safe?"
The three possible answers and their response rates were:
The fact is that your bank's web site uses TLS to provide an end-to-end secure connection, encrypted and authenticated. There is a possibility that your bank has TLS configured incorrectly, for example by still allowing old versions SSL3 and even SSL2 which have known weaknesses, but it's actually pretty low. Most all banks get this right. If you wonder about yours, there are some free services that check for you. For example, https://www.ssllabs.com/ssltest/.
(Note that the SSLLabs testing protocol is fairly harsh, which is good but perhaps a bit alarmist. If your bank gets a B or a C, scroll down in the report and take a look at the results of simulations with the browser you use. One of the banks I use (Chase) gets a B because it supports use of RC4. Now RC4 isn't actually insecure when used correctly, and TLS does use it correctly, but it's old and no longer recommended. However, my browser (Chrome 47), does not use RC4, so the site/browser combination is green, meaning secure. Some sites also get dinged for not supporting forward secrecy. That's a nice property, but not essential. Don't worry about it.)
So why were the others wrong?
The second option, reading CNN or similar, is wrong because almost no news sites use TLS at all. They're all unencrypted and unauthenticated. This makes them risky all the time, because any attacker anywhere in the chain of routers and servers between you and the origin site can alter the data you receive from them, injecting malware to exploit your browser, tracking cookies (from any origin), drive-by downloads, etc. An attacker can also extract authentication cookies from your browser, for any non-TLS sites you use even without any browser vulnerabilities. But non-TLS sites are particularly risky when you're connected to a random Wifi AP because that is an ideal way for someone to mount these sorts of attacks.
The third option, "just say no", is one I have some sympathy for. And, as the comments on my original post pointed out, it actually may be a correct answer depending on how you interpret "safe". TLS doesn't protect the Wifi operator from seeing what sites you visit, for example, and that list can say a lot about you even if none of your actual information is revealed and even if the data sent to your browser can't be manipulated in dangerous ways. However, if being tracked online is your major concern, you probably just shouldn't use the web at all, unfortunately, so I'm going to discard that definition of "safe". Under a more common interpretation which is that your traffic can't be snooped or your computer (or mobile device) harmed by what you receive, this option is wrong because connecting to your bank, with an up-to-date browser and assuming decent configuration on the bank side, *is* safe, and the "just say no" stance would unnecessarily restrict you.
Others in the comments tried to add additional options to the poll, suggesting that it was safe to use a VPN to a trusted gateway. This is true, but HTTP sites are still inherently less secure than HTTPS sites. Use of the VPN removes the possibly-unscrupulous Wifi operator from the equation, but an attacker who manages to get between the VPN server and CNN can still do anything. Security really needs to be end-to-end.
An interesting point related to VPNs is that Google's security team is eliminating their use for Google employees. Google used to deploy VPN software on almost all portable corporate devices so that employees could securely connect to company systems while traveling, or from home. A couple of years ago they recognized that this was an unnecessary complication and instead they've worked to expose all of the internal systems directly on the Internet, but accessible only via HTTPS (and with tight TLS configurations). Client certificates are issued to corporate devices, and the TLS configuration is set to reject any connection that doesn't have a valid certificate. Actually "exposed" isn't quite the right word, because what's really directly connected to the Internet is a reverse proxy which does the TLS and also implements user authentication (after the connection is established and client cert is verified) using user password and two-factor authentication. The 2FA used in most cases is cryptographic, not a password, from a hardware token (a "security key"). The actual systems receive information from the proxy about what user connected, and don't need to handle any of the TLS or authentication themselves. It's quite elegant, very secure, all standards-based, and doesn't require VPN software, just a modern web browser. Also, _exactly_ the same technology is used for connections coming from inside the corporate network. There's no need to distinguish between "outside" and "inside"; just secure it all.
By the way, I sometimes run into people who don't believe that everything on the web should be encrypted, because lots of stuff just isn't that important. They're wrong. We really need to encrypt and authenticate all Internet traffic.
Yesterday I posted a Google+ poll about what is and isn't safe on an unknown Wifi access point, and 93% of the 30 responses were wrong, in spite of the fact that many of the people who follow me are technical and even have a security bent. This did not surprise me.
The question was "You're connected to some random public Wifi hotspot. You know nothing about who owns it or why they make it public (the SSID says it's STARBUCKS and there is a nearby Starbucks, but who knows?), but it gives you a functional Internet connection. Which of the following is safe?"
The three possible answers and their response rates were:
- Logging onto your bank to transfer money (7%)
- Reading the news on CNN, or similar (27%)
- None of the above, unknown Wifi is risky (67%)
The right answer is "Logging onto your bank to transfer money". Congrats to the two voters who got it right.
(Note that the SSLLabs testing protocol is fairly harsh, which is good but perhaps a bit alarmist. If your bank gets a B or a C, scroll down in the report and take a look at the results of simulations with the browser you use. One of the banks I use (Chase) gets a B because it supports use of RC4. Now RC4 isn't actually insecure when used correctly, and TLS does use it correctly, but it's old and no longer recommended. However, my browser (Chrome 47), does not use RC4, so the site/browser combination is green, meaning secure. Some sites also get dinged for not supporting forward secrecy. That's a nice property, but not essential. Don't worry about it.)
So why were the others wrong?
The second option, reading CNN or similar, is wrong because almost no news sites use TLS at all. They're all unencrypted and unauthenticated. This makes them risky all the time, because any attacker anywhere in the chain of routers and servers between you and the origin site can alter the data you receive from them, injecting malware to exploit your browser, tracking cookies (from any origin), drive-by downloads, etc. An attacker can also extract authentication cookies from your browser, for any non-TLS sites you use even without any browser vulnerabilities. But non-TLS sites are particularly risky when you're connected to a random Wifi AP because that is an ideal way for someone to mount these sorts of attacks.
The third option, "just say no", is one I have some sympathy for. And, as the comments on my original post pointed out, it actually may be a correct answer depending on how you interpret "safe". TLS doesn't protect the Wifi operator from seeing what sites you visit, for example, and that list can say a lot about you even if none of your actual information is revealed and even if the data sent to your browser can't be manipulated in dangerous ways. However, if being tracked online is your major concern, you probably just shouldn't use the web at all, unfortunately, so I'm going to discard that definition of "safe". Under a more common interpretation which is that your traffic can't be snooped or your computer (or mobile device) harmed by what you receive, this option is wrong because connecting to your bank, with an up-to-date browser and assuming decent configuration on the bank side, *is* safe, and the "just say no" stance would unnecessarily restrict you.
Others in the comments tried to add additional options to the poll, suggesting that it was safe to use a VPN to a trusted gateway. This is true, but HTTP sites are still inherently less secure than HTTPS sites. Use of the VPN removes the possibly-unscrupulous Wifi operator from the equation, but an attacker who manages to get between the VPN server and CNN can still do anything. Security really needs to be end-to-end.
An interesting point related to VPNs is that Google's security team is eliminating their use for Google employees. Google used to deploy VPN software on almost all portable corporate devices so that employees could securely connect to company systems while traveling, or from home. A couple of years ago they recognized that this was an unnecessary complication and instead they've worked to expose all of the internal systems directly on the Internet, but accessible only via HTTPS (and with tight TLS configurations). Client certificates are issued to corporate devices, and the TLS configuration is set to reject any connection that doesn't have a valid certificate. Actually "exposed" isn't quite the right word, because what's really directly connected to the Internet is a reverse proxy which does the TLS and also implements user authentication (after the connection is established and client cert is verified) using user password and two-factor authentication. The 2FA used in most cases is cryptographic, not a password, from a hardware token (a "security key"). The actual systems receive information from the proxy about what user connected, and don't need to handle any of the TLS or authentication themselves. It's quite elegant, very secure, all standards-based, and doesn't require VPN software, just a modern web browser. Also, _exactly_ the same technology is used for connections coming from inside the corporate network. There's no need to distinguish between "outside" and "inside"; just secure it all.
By the way, I sometimes run into people who don't believe that everything on the web should be encrypted, because lots of stuff just isn't that important. They're wrong. We really need to encrypt and authenticate all Internet traffic.
Thursday, August 27, 2015
Jace's Grade Monitor
My youngest son is a bright kid, but doesn't have much interest in school. He's in 8th grade. It's easy enough for him, but he'd rather play games or watch TV. That has caused him to struggle in school, and resulted in lots of tear-filled evenings when he gets to do nothing but homework because he's behind.
Our solution is to ground him from video games and TV if he's behind in school... and to specify that he isn't allowed to do any of that stuff after school until he's done his homework, but it's pretty hard for us to enforce that, since we don't have up-to-date information on what he's assigned and what he's turned in. We can find out if he's behind or his grades are slipping, though, by looking at the school's on-line gradebook. So, the rule is that if that shows he's behind, or his grades are too low, then he's grounded.
But even that is something of a pain, because it requires us (well, Kristanne) to regularly check the web site, which is often down and almost always slow. And if she's not home when he gets home from school he doesn't know if he's currently behind.
I decided that this problem can be solved with technology. There are several ways I could go about it. I could write a phone app, or put something on the kids' computer. I decided to go with something less subtle: A multi-color LED in the kitchen that shows his current status at all times. If his grades are good, it's green. If they begin to fall, it shades towards yellow and then red. If he's missing assignments, it flashes a count of the missing assignments in blue.
The result is a crude, hack-and-slash assembly of some pretty cool technology. I threw it together in an evening, including learning how to install and configure all the components and write all the code. The components are:


Our solution is to ground him from video games and TV if he's behind in school... and to specify that he isn't allowed to do any of that stuff after school until he's done his homework, but it's pretty hard for us to enforce that, since we don't have up-to-date information on what he's assigned and what he's turned in. We can find out if he's behind or his grades are slipping, though, by looking at the school's on-line gradebook. So, the rule is that if that shows he's behind, or his grades are too low, then he's grounded.
But even that is something of a pain, because it requires us (well, Kristanne) to regularly check the web site, which is often down and almost always slow. And if she's not home when he gets home from school he doesn't know if he's currently behind.
I decided that this problem can be solved with technology. There are several ways I could go about it. I could write a phone app, or put something on the kids' computer. I decided to go with something less subtle: A multi-color LED in the kitchen that shows his current status at all times. If his grades are good, it's green. If they begin to fall, it shades towards yellow and then red. If he's missing assignments, it flashes a count of the missing assignments in blue.
The result is a crude, hack-and-slash assembly of some pretty cool technology. I threw it together in an evening, including learning how to install and configure all the components and write all the code. The components are:
- A Raspberry Pi 2, (RP2) a small quad-core 700 Mhz ARM computer with 1 GiB of ram and a 32 GiB SD card. It runs Debian Linux.
- A Spark core, which is an Arduino board with built-in Wifi and an interesting development toolset.
- A red-green-blue LED.
- Some resistors to avoid blowing up the LED. I used 330 ohm resistors, which are too big, which means the LED is dimmer than it could be. Oh, well.
My original plan was not to use the Spark, but to wire the LED directly to the GPIO pins on the RP2. But the GPIO headers were male, which means I need a ribbon cable or something else to make it easier to wire them (or I could have soldered wires to them, but that sounded too much like work). So instead I connected the LED to the Spark and I'm using the RP2 to control it.
Here's what the RP2 looks like, in the nifty black case I got for it:

The dongle hanging out the right end is USB Wifi adapter. It's also got an Ethernet jack, if I want to put it where it can be wired.
And here's the LED connected to the Spark core, on a breadboard, with the all-important grade status LED:

For now I just set the whole thing on top of the printer. I'll think about doing something nicer later.
How does it work? The RP2 has a cron job that runs a small script. The script uses curl to download the web page with the grade and assignment information, then pipes it to a Python program that parses the HTML and extracts and summarizes the grade and missing assignment info. The output from the Python program is then used for two more curl invocations, which post the computed values to a server run by Particle. They make the Spark core.
The Particle server routes the data to the Spark, which is running a trivial Arduino program. Normally you compile Arduino code on your computer and download it to the device via USB. You can do that with the Spark, but for small stuff it's easier to use their web-based tools. They provide a web-based editor into which you type your code, then you click a button and they compile the code to a binary and send it over the Internet to the Spark, which flashes it and reboots.
All very hack and slash... but it works and it was really easy. The Sparks are pretty cheap, too ($12, IIRC). I have another I'm going to wire into my garage door controller to do some automation on it (because the kids keep leaving the garage open).
Sunday, July 20, 2014
House Site Plan
I don't even want to think about how many hours it took me to put this together.
The county building permit application, the power company service application, the health department application and probably a few others have all required a site plan for my new house. Drawing a simple plan is easy, but the county wants detailed, two-foot contour lines. Obviously, there is no place I can go to get a two-foot contour plot of my property. I contacted a surveyor, but he wanted almost $2K to make me a contour plot.
I figured, how hard can it be?
Well, hard. But it's done. Here's the final version:

To get contour lines, I took a handheld GPS unit with a barometric altimeter and walked the property. And walked, and walked, and walked. As you can see from the final diagram, the land is far from flat. In fact I now know that the total elevation change is 160 feet. But to gather data, I needed to cris-cross the property many, many times, ideally gathering a position and elevation data point every few feet. I walked the whole thing four times, and the last time I walked it I covered six miles and climbed over 2000 feet.
The reason I walked it multiple times was partly because I was learning how to do it, and partly because GPS receivers aren't that accurate. I needed lots of data to help correct for the inaccuracy. GPS is particularly inaccurate when it comes to elevation, but that's why the units I used contain an electronic barometer. The barometer doesn't give them much information about absolute elevation (you can estimate elevation from air pressure, but it's even less precise than GPS elevation), but it provides them fairly precise information about relative elevation. That's what I need. I don't care how far above sea level the property is, I care about how much higher this part is than that part.
GPS receivers also have a fair amount of latitude and longitude error as well. I couldn't find any detailed information about the distribution of the error -- which may actually be different for different devices -- so I assumed it's probably normally distributed and can be reduced by averaging multiple samples together. Because GPS is based on very precise measurements of time signals, if you have multiple GPS receivers you can be guaranteed that they have synchronized time. It may not match up perfectly to wall clock time due to minor adjustments that get made to our clocks, but you can be sure the GPS units all agree.
So, I carried two identical Garmin Rino 130 receivers while I walked. The reason I had two identical ones is because the Rinos are actually walkie-talkies, not just GPS receivers, so it's quite useful to have more than one. But I carried both of them side by side.
After I got back and got the data off them (from all of the multiple runs), I first edited the track logs to remove extraneous data from before and after I started walking. Then I imported the mess into Mathematica. Next, I translated all of the points to try to correct for the fact that every time, every receiver, had the whole property shifted by a few feet in one direction or another. That was actually pretty easy to handle; I took waypoints at each of the corners, on each GPS, during each walk. I picked one of them (the westmost corner) to be my point of reference, and translated each log so that those points matched up.
Actually, I went one further, and translated all of them so that that corner point is (0,0). But more data munging was required. GPS coordinates are recorded as (latitude, longitude), which means they're (y,x), rather than (x,y). So I had to rotate all of the points 90 degrees around my origin to get to (x,y).
Next, I want all the distances on my map to be scaled so that measurements in any direction are valid. That means that one inch on the map should represent a fixed number of feet, no matter whether your ruler is measuring right to left (west to east) or bottom to top (south to north). But latitude and longitude aren't "square" like that in most places. In the area around my property, a millidegree of latitude is approximately 111 meters, and a millidegree of longitude is approximately 84 meters. So the "aspect ratio", the non-squareness, of my coordinate system is about 1.32. So I also scaled all of the y coordinates to "square up" my coordinates. As a result the Euclidean distance between any two points on the map provides a pretty good estimate of the straight-line distance between the real-world points they represent. This sort of scaling to square up only works across relatively small areas, but it's fine for my purposes.
For each walk, I now had two normalized logs, one from each GPSr. I combined them by matching timestamps and averaged the (x,y,z) coordinates from the pair of logs. Mostly. I found a few cases where one of the two devices wandered off and started giving very strange data, so I went back and deleted those points. There was actually a lot of hand-editing of the data to clean up various problems. Here's what I had at this point:

The result is obviously still spotty in some areas, which led to odd-looking contour plots. To fix that, I resampled the entire area at consistent intervals, and for each resampled point I used the mean of the nearest (in (x,y) only) five points. This actually helped with another problem: The fact that the data ends abruptly at the property lines tends to cause the contour plot generation algorithm to do funky things near the edge. My resampling technique resampled the area around the property as well, using the nearest data points. This "extra" data is, of course, complete nonsense, but it's nonsense which is much closer to reality than nothingness, which made the contour plotter happier.
Here's the resampled data, resampled at 200 points on a side, so 40K points total:

There's some waviness towards the center which isn't actually there. I started trying to figure out where it came from and how to smooth it back out, but ultimately decided it didn't matter, because I found that to get nice contour plots I really needed to scale back the level of detail, otherwise the lines were too "jagged". Using a resampling with 30 points on each side, 900 points, here's a contour plot, with the number of contour lines set to provide a vertical distance of two feet per line:

This isn't bad, but the contour lines are still a little too jagged. Applying some rather arbitrary smoothing to the lines, removing the color and cropping to the property lines gives this:

That actually looks really good. I have no doubt that there are some small errors, in fact I can point out some oddities which are almost certainly wrong, but it's the large features match up perfectly.
Good enough. What came next was really time-consuming. I had to add all of the additional details. Among other things, that meant taking the measurements from the house plans and putting them in to create an accurate rendition of the shape of the house, and then placing it in what seems like the right place on the map. Here's the house, already rotated to the right angle for placement on the map. Note that although this image is scale-free, the measurements are actually in my squared-up millidegrees, so when it's superimposed on the contour map, the measurements are all correct.

The enormous gray "turn pad", BTW, is a feature demanded by the fire marshal. I have to provide a hard surface large enough to turn a fire engine around, and that's it. The marshal said I needed 45 feet on a side, that pad is 45x55. I had to lengthen it a bit because of the decorative extension which comes 9 feet off the house. So actual clear turning space is 45x46.
Then I had to add in the well and septic field, barn, driveway, road and all of the "setback" and building size measurements, to produce the final version above.
Mathematica is an awesome tool, and I don't think I could have accomplished this without it. But it was still a lot of work. Okay, so I have thought about how many hours I put in and I'm sure it's around 60. I suppose that's better than spending $2,000. I'll keep telling myself that. Probably 20 of those hours were fun. The rest, not so much.
The county building permit application, the power company service application, the health department application and probably a few others have all required a site plan for my new house. Drawing a simple plan is easy, but the county wants detailed, two-foot contour lines. Obviously, there is no place I can go to get a two-foot contour plot of my property. I contacted a surveyor, but he wanted almost $2K to make me a contour plot.
I figured, how hard can it be?
Well, hard. But it's done. Here's the final version:
To get contour lines, I took a handheld GPS unit with a barometric altimeter and walked the property. And walked, and walked, and walked. As you can see from the final diagram, the land is far from flat. In fact I now know that the total elevation change is 160 feet. But to gather data, I needed to cris-cross the property many, many times, ideally gathering a position and elevation data point every few feet. I walked the whole thing four times, and the last time I walked it I covered six miles and climbed over 2000 feet.
The reason I walked it multiple times was partly because I was learning how to do it, and partly because GPS receivers aren't that accurate. I needed lots of data to help correct for the inaccuracy. GPS is particularly inaccurate when it comes to elevation, but that's why the units I used contain an electronic barometer. The barometer doesn't give them much information about absolute elevation (you can estimate elevation from air pressure, but it's even less precise than GPS elevation), but it provides them fairly precise information about relative elevation. That's what I need. I don't care how far above sea level the property is, I care about how much higher this part is than that part.
GPS receivers also have a fair amount of latitude and longitude error as well. I couldn't find any detailed information about the distribution of the error -- which may actually be different for different devices -- so I assumed it's probably normally distributed and can be reduced by averaging multiple samples together. Because GPS is based on very precise measurements of time signals, if you have multiple GPS receivers you can be guaranteed that they have synchronized time. It may not match up perfectly to wall clock time due to minor adjustments that get made to our clocks, but you can be sure the GPS units all agree.
So, I carried two identical Garmin Rino 130 receivers while I walked. The reason I had two identical ones is because the Rinos are actually walkie-talkies, not just GPS receivers, so it's quite useful to have more than one. But I carried both of them side by side.
After I got back and got the data off them (from all of the multiple runs), I first edited the track logs to remove extraneous data from before and after I started walking. Then I imported the mess into Mathematica. Next, I translated all of the points to try to correct for the fact that every time, every receiver, had the whole property shifted by a few feet in one direction or another. That was actually pretty easy to handle; I took waypoints at each of the corners, on each GPS, during each walk. I picked one of them (the westmost corner) to be my point of reference, and translated each log so that those points matched up.
Actually, I went one further, and translated all of them so that that corner point is (0,0). But more data munging was required. GPS coordinates are recorded as (latitude, longitude), which means they're (y,x), rather than (x,y). So I had to rotate all of the points 90 degrees around my origin to get to (x,y).
Next, I want all the distances on my map to be scaled so that measurements in any direction are valid. That means that one inch on the map should represent a fixed number of feet, no matter whether your ruler is measuring right to left (west to east) or bottom to top (south to north). But latitude and longitude aren't "square" like that in most places. In the area around my property, a millidegree of latitude is approximately 111 meters, and a millidegree of longitude is approximately 84 meters. So the "aspect ratio", the non-squareness, of my coordinate system is about 1.32. So I also scaled all of the y coordinates to "square up" my coordinates. As a result the Euclidean distance between any two points on the map provides a pretty good estimate of the straight-line distance between the real-world points they represent. This sort of scaling to square up only works across relatively small areas, but it's fine for my purposes.
For each walk, I now had two normalized logs, one from each GPSr. I combined them by matching timestamps and averaged the (x,y,z) coordinates from the pair of logs. Mostly. I found a few cases where one of the two devices wandered off and started giving very strange data, so I went back and deleted those points. There was actually a lot of hand-editing of the data to clean up various problems. Here's what I had at this point:
The result is obviously still spotty in some areas, which led to odd-looking contour plots. To fix that, I resampled the entire area at consistent intervals, and for each resampled point I used the mean of the nearest (in (x,y) only) five points. This actually helped with another problem: The fact that the data ends abruptly at the property lines tends to cause the contour plot generation algorithm to do funky things near the edge. My resampling technique resampled the area around the property as well, using the nearest data points. This "extra" data is, of course, complete nonsense, but it's nonsense which is much closer to reality than nothingness, which made the contour plotter happier.
Here's the resampled data, resampled at 200 points on a side, so 40K points total:
There's some waviness towards the center which isn't actually there. I started trying to figure out where it came from and how to smooth it back out, but ultimately decided it didn't matter, because I found that to get nice contour plots I really needed to scale back the level of detail, otherwise the lines were too "jagged". Using a resampling with 30 points on each side, 900 points, here's a contour plot, with the number of contour lines set to provide a vertical distance of two feet per line:
This isn't bad, but the contour lines are still a little too jagged. Applying some rather arbitrary smoothing to the lines, removing the color and cropping to the property lines gives this:
That actually looks really good. I have no doubt that there are some small errors, in fact I can point out some oddities which are almost certainly wrong, but it's the large features match up perfectly.
Good enough. What came next was really time-consuming. I had to add all of the additional details. Among other things, that meant taking the measurements from the house plans and putting them in to create an accurate rendition of the shape of the house, and then placing it in what seems like the right place on the map. Here's the house, already rotated to the right angle for placement on the map. Note that although this image is scale-free, the measurements are actually in my squared-up millidegrees, so when it's superimposed on the contour map, the measurements are all correct.
The enormous gray "turn pad", BTW, is a feature demanded by the fire marshal. I have to provide a hard surface large enough to turn a fire engine around, and that's it. The marshal said I needed 45 feet on a side, that pad is 45x55. I had to lengthen it a bit because of the decorative extension which comes 9 feet off the house. So actual clear turning space is 45x46.
Then I had to add in the well and septic field, barn, driveway, road and all of the "setback" and building size measurements, to produce the final version above.
Mathematica is an awesome tool, and I don't think I could have accomplished this without it. But it was still a lot of work. Okay, so I have thought about how many hours I put in and I'm sure it's around 60. I suppose that's better than spending $2,000. I'll keep telling myself that. Probably 20 of those hours were fun. The rest, not so much.
Wednesday, April 16, 2014
Front Sight Four-day Handgun Course
I got home yesterday from a four-day handgun course at Front Sight in Pahrump, NV (http://frontsight.com). My brief review is: Excellent class, well worth the time, I'd recommend it to anyone who wants to improve their handgun skills.
This is a basic but thorough defensive handgun class. It's basic in that it doesn't try to cover much more than how to draw, shoot, after action and fix malfunctions. It's thorough in that it covers those topics in great depth, teaches you how to build the right muscle memory to do the tactically-correct things under stress and takes you a good way toward actually building that muscle memory, to the degree that most students can draw, aim and fire two aimed shots to center mass of a man-sized silhouette at five meters, all in under 1.5 seconds.
The class is appropriate for everyone from complete novices to experienced handgun shooters. Indeed a friend of mine who is an advanced defensive handgun instructor took it and found it interesting and useful. The class made me a better shooter, and I also picked up a lot of ideas from the way the instructors presented the material and the way they ran the range -- it was very well done and there were a lot of great ideas which will make me a better handgun instructor.
The course covers, safety, presentation, after action, reloading (tactical and emergency) and malfunction clearance (types 1, 2 and 3). It drills the students intensively in those skills, under time pressure to simulate combat stress and develop fluidity and speed. I'll cover each of these briefly, highlighting the areas in which Front Sight's approach differs from others.
Safety. Like any gun school that wants to stay in business Front Sight is very, very careful about safety. The rules are Cooper's normal four rules (I still think rule #1 is pointless and perhaps dangerous, but I didn't argue with them). They do differ by adding some extra and, I think, wise procedures. One important one is the "chamber-check mag-check" process, which they stress is always done as a unit. You never check the chamber without also checking the magazine, even when one or the other is unnecessary, and you always do them the same way and in the same order, because that way you'll never forget one of them when it is necessary. Another is that the "chamber-check mag-check" process must always be performed both before and after changing the state of the gun (loading or unloading), as well as after picking up and before putting a gun down or away.
Presentation. "Presentation" is the fancy (but common, in gun circles) word for drawing the gun from the holster and getting it either into a ready position or in position to shoot. Front Sight teaches a fairly standard five-count presentation. The five counts are:
Shooting. Front Sight teaches a modified Weaver stance (aka Chapman stance) with the body bladed at 30° from the target, shooting side shoulder back, shooting arm straight, support arm bent. I'm more comfortable with the isoceles stance, so this was difficult for me at first. I could have insisted on my preferred stance, and they'd have been fine with it, but I decided to go along. It worked quite well after I got used to it, but I don't know that I'll stick with it. I need to spend some time experimenting. They also stress follow-through, including trapping the trigger to the rear (continuing the trigger press all the way back, even after the gun has gone off), and reaquiring the sight picture immediately. That's all quite obvious, but I hadn't realized that I have a tendency to skimp on followthrough when I know I'm not going to fire another shot. I'm mostly cured of that, I think.
Like all defensive (and offensive) shooting trainers everywhere, Front Sight teaches shooting to center mass, and specifically to the thoracic cavity (basically everything included inside the rib cage). They also teach shooting "controlled pairs", meaning two shots, followed by a pause to assess. Note that this isn't the same as a double tap, because they teach slowing down between the shots enough to reacquire the sight picture. Under the stress of the brief shoothouse exercise I found I fell back on double tapping. The instructor corrected me.
However, they also teach the "failure to stop" shot, which is a carefully-aimed head shot (specifically to the cranio-ocular cavity, the region between eyebrows and bottom of the nose), to be used when the controlled pair to the thoracic cavity fails to stop, for example if the target is wearing body armor, or is drugged or just sufficiently determined to shrug off the body shots. During shooting drills, the instructor will occasionally yell "Head!", indicating the need for a failure to stop shot. They also teach designated head shots, for cases of hostage situations where the bad guy is mostly shielded behind a hostage.
They are quite clear throughout, though, that the goal of defensive shooting is to stop the attacker, not to kill, and point out that given rapid attention from a fully-equipped trauma center, a person who has received two shots to the thoracic cavity has a roughly 80% chance of survival -- and that's a good thing. I very much approved of the emphasis they put on this, and the way they were quick to step on any talk of shooting to kill. Of course, a head shot is almost invariably fatal, but those are presented as shots of last resort, to be used only when nothing else will do.
After Action. Front Sight teaches a pretty standard after-action process for after the final shot is fired, with lateral movement (to force the opponent to reacquire his sight picture and/or move to cover or concealment), followed by a quick check of the area for additional threats, then a more detailed study of the target to verify that the threat is ended, then a 360° scan to verify the situation really is safe before reholstering the gun. Of course, in the confines of a small range, opportunities for lateral movement are limited to a sidestep to left or right and the 360° scan is limited to a narrow wedge downrange. But within those limitations, the instructors are diligent about ensuring that everyone makes the after action drill a part of every shot sequence, to ingrain it.
They also constantly push to include a tactical reload as the last step of the after action drill. This just means replacing the partially-expended magazine in the gun with a full one, but retaining the partial in a pocket rather than dropping it to the ground. Of course they also teach how to do this smoothly and quickly. I am dramatically faster at loading a new magazine than I was before the class, and can do it in a single motion, from belt to gun, without looking and without lowering the gun from the firing position. And in a fraction of a second. It's a lot easier than I thought... and I already knew it was easy.
(Aside: anyone who thinks that limiting magazine size will significantly impede the ability of active shooters to carry out their rampage should get two minutes of training on how to reload and then spend 15 minutes practicing it.)
Malfunctions. Front Sight teaches and tests (timed!) clearing type 1, 2 and 3 malfunctions, which are failure to fire, failure to eject and failure to feed, respectively. They also incorporate tactical movement into the type 2 and 3 malfunction processes. Into the malfunction training they also add emergency reloads, which is reloading when your gun runs dry and the slide locks back on an empty chamber. This is quite similar to a tactical reload except that the empty magazine is allowed to fall to the ground, and it is not released to drop until the new magazine is already rising to be inserted, so that by the time the opponent has realized you're empty (from the falling magazine), you're no longer empty.
All four days of the course are long and tiring. In the process, you shoot approximately 600 rounds, which means you have to take advantage of any down time to reload magazines. In addition to the range training there are also lectures on firearm selection, combat attitude and mindset, what to do after a gunfight and more. Some of the lectures are sales pitches (SportEar and Legal Shield), but they seem like pretty good products.
The last day includes a fun steel shooting competition among the class members (my class had no winner because both of the finalists shot the hostage), and then the final skills test. The test is fairly difficult. In my class of 40, only eight students passed, plus one who got "distinguished graduate" marks. It requires shooting controlled pairs, under time pressure, from 5, 7, 10 and 15 meters, plus some untimed "failure to stop" head shots at 5 and 7 meters. Then there are a series of timed "designated head shots" at 5 and 7 meters. The times vary depending on distance and type of shot. All are doable, but not in any way generous. The 5 meter controlled pair time is 1.5 seconds, for example, and that includes clearing the cover garment out of the way, drawing, aiming and firing.
I passed, and was one point away from getting distinguished graduate. If any one of three bullets had struck a quarter inch higher on my designated head shots, I'd have made it with points to spare (I lost three points for each of those bullets). My group was tight, about 3/4" across, but low, so it straddled the lower boundary of the line delineating the cranio-ocular cavity. I think I'm yanking the last fraction of an inch on the trigger, pulling the gun down slightly just before it goes off.
Having passed that class, I'm now eligible to take the advanced class, but I think I'd prefer to go to the two-day skill builder class to further tune up my shooting -- and get to the distinguished graduate level. In actual fact, though I think the next class I take will probably be the four-day precision rifle class.
One thing is pretty clear, though, I will be going back. The facility is clean and extremely well-organized, the instructors are friendly, competent and focused on helping students get the most they can out of the class while having a good time and the curriculum is well-designed and well-structured. The days are long and tiring, but fun, and I learned a tremendous amount. I still think the owner, Ignatius Piazza, has a late night infomercial marketing style that is extremely off-putting, and I have serious concerns about whether or not they can continue operating the way they are at the prices I paid, but I have no reservations about the facility, staff or training.
This is a basic but thorough defensive handgun class. It's basic in that it doesn't try to cover much more than how to draw, shoot, after action and fix malfunctions. It's thorough in that it covers those topics in great depth, teaches you how to build the right muscle memory to do the tactically-correct things under stress and takes you a good way toward actually building that muscle memory, to the degree that most students can draw, aim and fire two aimed shots to center mass of a man-sized silhouette at five meters, all in under 1.5 seconds.
The class is appropriate for everyone from complete novices to experienced handgun shooters. Indeed a friend of mine who is an advanced defensive handgun instructor took it and found it interesting and useful. The class made me a better shooter, and I also picked up a lot of ideas from the way the instructors presented the material and the way they ran the range -- it was very well done and there were a lot of great ideas which will make me a better handgun instructor.
The course covers, safety, presentation, after action, reloading (tactical and emergency) and malfunction clearance (types 1, 2 and 3). It drills the students intensively in those skills, under time pressure to simulate combat stress and develop fluidity and speed. I'll cover each of these briefly, highlighting the areas in which Front Sight's approach differs from others.
Safety. Like any gun school that wants to stay in business Front Sight is very, very careful about safety. The rules are Cooper's normal four rules (I still think rule #1 is pointless and perhaps dangerous, but I didn't argue with them). They do differ by adding some extra and, I think, wise procedures. One important one is the "chamber-check mag-check" process, which they stress is always done as a unit. You never check the chamber without also checking the magazine, even when one or the other is unnecessary, and you always do them the same way and in the same order, because that way you'll never forget one of them when it is necessary. Another is that the "chamber-check mag-check" process must always be performed both before and after changing the state of the gun (loading or unloading), as well as after picking up and before putting a gun down or away.
Presentation. "Presentation" is the fancy (but common, in gun circles) word for drawing the gun from the holster and getting it either into a ready position or in position to shoot. Front Sight teaches a fairly standard five-count presentation. The five counts are:
- Acquire a shooting grip on the holstered gun. The support hand goes to the midsection at the same time. If the gun is concealed, the concealment needs to be cleared first. One tidbit I learned: if you're going for speed, focus on moving your support hand faster. It's a simpler motion, easier to speed up, and sympathetic response will move your gun hand faster, too.
- Draw the gun from the holster, moving it straight up to just below the armpit, but leaving it pointed downward. The support hand stays on the midsection.
- Rotate the muzzle up and forward. The support hand stays put.
- Move the support hand to join the shooting hand on the gun.
- Extend the gun outward into position. If moving into firing position, as the gun moves outward the trigger finger moves into the trigger guard and takes up the slack on the trigger. As it rises, the eyes find first the front sight post and then acquires an aligned sight picture. The sights should be aligned and on the target before the gun is fully extended. By the time the gun reaches full extension, all that remains to fire is to finish the trigger press.
Shooting. Front Sight teaches a modified Weaver stance (aka Chapman stance) with the body bladed at 30° from the target, shooting side shoulder back, shooting arm straight, support arm bent. I'm more comfortable with the isoceles stance, so this was difficult for me at first. I could have insisted on my preferred stance, and they'd have been fine with it, but I decided to go along. It worked quite well after I got used to it, but I don't know that I'll stick with it. I need to spend some time experimenting. They also stress follow-through, including trapping the trigger to the rear (continuing the trigger press all the way back, even after the gun has gone off), and reaquiring the sight picture immediately. That's all quite obvious, but I hadn't realized that I have a tendency to skimp on followthrough when I know I'm not going to fire another shot. I'm mostly cured of that, I think.
Like all defensive (and offensive) shooting trainers everywhere, Front Sight teaches shooting to center mass, and specifically to the thoracic cavity (basically everything included inside the rib cage). They also teach shooting "controlled pairs", meaning two shots, followed by a pause to assess. Note that this isn't the same as a double tap, because they teach slowing down between the shots enough to reacquire the sight picture. Under the stress of the brief shoothouse exercise I found I fell back on double tapping. The instructor corrected me.
However, they also teach the "failure to stop" shot, which is a carefully-aimed head shot (specifically to the cranio-ocular cavity, the region between eyebrows and bottom of the nose), to be used when the controlled pair to the thoracic cavity fails to stop, for example if the target is wearing body armor, or is drugged or just sufficiently determined to shrug off the body shots. During shooting drills, the instructor will occasionally yell "Head!", indicating the need for a failure to stop shot. They also teach designated head shots, for cases of hostage situations where the bad guy is mostly shielded behind a hostage.
They are quite clear throughout, though, that the goal of defensive shooting is to stop the attacker, not to kill, and point out that given rapid attention from a fully-equipped trauma center, a person who has received two shots to the thoracic cavity has a roughly 80% chance of survival -- and that's a good thing. I very much approved of the emphasis they put on this, and the way they were quick to step on any talk of shooting to kill. Of course, a head shot is almost invariably fatal, but those are presented as shots of last resort, to be used only when nothing else will do.
After Action. Front Sight teaches a pretty standard after-action process for after the final shot is fired, with lateral movement (to force the opponent to reacquire his sight picture and/or move to cover or concealment), followed by a quick check of the area for additional threats, then a more detailed study of the target to verify that the threat is ended, then a 360° scan to verify the situation really is safe before reholstering the gun. Of course, in the confines of a small range, opportunities for lateral movement are limited to a sidestep to left or right and the 360° scan is limited to a narrow wedge downrange. But within those limitations, the instructors are diligent about ensuring that everyone makes the after action drill a part of every shot sequence, to ingrain it.
They also constantly push to include a tactical reload as the last step of the after action drill. This just means replacing the partially-expended magazine in the gun with a full one, but retaining the partial in a pocket rather than dropping it to the ground. Of course they also teach how to do this smoothly and quickly. I am dramatically faster at loading a new magazine than I was before the class, and can do it in a single motion, from belt to gun, without looking and without lowering the gun from the firing position. And in a fraction of a second. It's a lot easier than I thought... and I already knew it was easy.
(Aside: anyone who thinks that limiting magazine size will significantly impede the ability of active shooters to carry out their rampage should get two minutes of training on how to reload and then spend 15 minutes practicing it.)
Malfunctions. Front Sight teaches and tests (timed!) clearing type 1, 2 and 3 malfunctions, which are failure to fire, failure to eject and failure to feed, respectively. They also incorporate tactical movement into the type 2 and 3 malfunction processes. Into the malfunction training they also add emergency reloads, which is reloading when your gun runs dry and the slide locks back on an empty chamber. This is quite similar to a tactical reload except that the empty magazine is allowed to fall to the ground, and it is not released to drop until the new magazine is already rising to be inserted, so that by the time the opponent has realized you're empty (from the falling magazine), you're no longer empty.
All four days of the course are long and tiring. In the process, you shoot approximately 600 rounds, which means you have to take advantage of any down time to reload magazines. In addition to the range training there are also lectures on firearm selection, combat attitude and mindset, what to do after a gunfight and more. Some of the lectures are sales pitches (SportEar and Legal Shield), but they seem like pretty good products.
The last day includes a fun steel shooting competition among the class members (my class had no winner because both of the finalists shot the hostage), and then the final skills test. The test is fairly difficult. In my class of 40, only eight students passed, plus one who got "distinguished graduate" marks. It requires shooting controlled pairs, under time pressure, from 5, 7, 10 and 15 meters, plus some untimed "failure to stop" head shots at 5 and 7 meters. Then there are a series of timed "designated head shots" at 5 and 7 meters. The times vary depending on distance and type of shot. All are doable, but not in any way generous. The 5 meter controlled pair time is 1.5 seconds, for example, and that includes clearing the cover garment out of the way, drawing, aiming and firing.
I passed, and was one point away from getting distinguished graduate. If any one of three bullets had struck a quarter inch higher on my designated head shots, I'd have made it with points to spare (I lost three points for each of those bullets). My group was tight, about 3/4" across, but low, so it straddled the lower boundary of the line delineating the cranio-ocular cavity. I think I'm yanking the last fraction of an inch on the trigger, pulling the gun down slightly just before it goes off.
Having passed that class, I'm now eligible to take the advanced class, but I think I'd prefer to go to the two-day skill builder class to further tune up my shooting -- and get to the distinguished graduate level. In actual fact, though I think the next class I take will probably be the four-day precision rifle class.
One thing is pretty clear, though, I will be going back. The facility is clean and extremely well-organized, the instructors are friendly, competent and focused on helping students get the most they can out of the class while having a good time and the curriculum is well-designed and well-structured. The days are long and tiring, but fun, and I learned a tremendous amount. I still think the owner, Ignatius Piazza, has a late night infomercial marketing style that is extremely off-putting, and I have serious concerns about whether or not they can continue operating the way they are at the prices I paid, but I have no reservations about the facility, staff or training.
Monday, March 24, 2014
First actual automation project, part 1
I've breadboarded up a few circuits containing various sensors, relays and LEDs, mostly to get some ideas about what I can realistically do with my custom home automation project. As a next step, I decided it would be a good idea to build something simple, and an obvious choice was to continue with an experiment I'd already begun: a "scent lamp".







Kristanne has a small incandescent lamp with a reservoir on top in which she puts scented candle wax. The heat from the bulb melts the wax. This lamp annoys me regularly because she turns it on during the day and then I go to bed, realize the darned thing is still on, and have to get out of bed to go turn it off. For myself, I don't enjoy the scented wax all that much and I'd just as soon get rid of it. But, she likes it, so I want to see if I can automate the thing to make it nicer for both of us.
The Lamp
I've already used this lamp to experiment with controlling a relay, since it was a convenient, low-powered target for my experiment.
What I decided I'd like the lamp to do is to:
- Turn on during the day and off at night, automatically. This is a backwards from most light controls but it makes sense (and scents, hyuck, hyuck) in this case.
- Turn on at night when it detects movement. The idea is that when one of us gets up in the middle of the night, the lamp should turn on. It's a small lamp, and not very bright (I believe the bulb is only 30W), so it won't be blinding, but it should provide enough light to be useful.
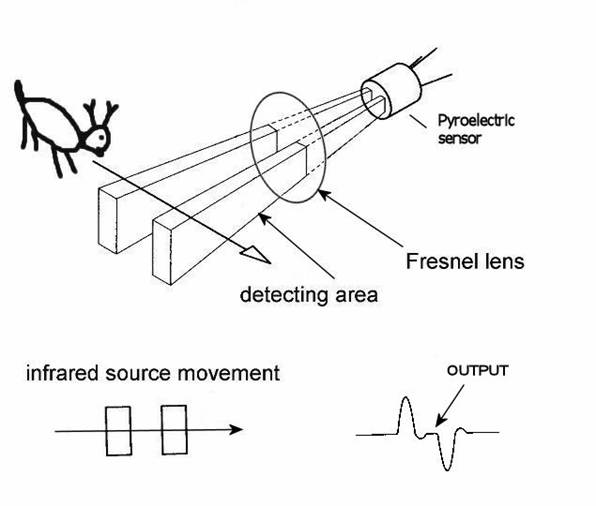
A PIR motion detector consists of a pair of small thermal sensors, adjacent to one another and wired so that the signal that emerges from the pair is the difference between the two. So, as long as both of them are seeing the infrared radiation levels, there's no signal. But when a warm body emitting IR radiation in the right frequency moves in front of them, one sensor will see the heat before the other, which means the difference signal will be non-zero.
However, the two IR sensor windows are thin slits, which means that the sensors have a fairly narrow angle of detection. So, PIR sensors come with a rounded Fresnel lens which bends IR light coming from various angles towards the sensor windows.
The fact that they're two parallel slits also means their ability to detect motion depends on which direction it's moving. If the slits are vertical, positioned side by side, then horizontal movement in front of them will be detected by one before the other, and the movement will register. But a heat source moving vertically into their field of view will be seen by both at once, and no response will be triggered.
So, by removing the Fresnel lens I can narrow the detection field, and by positioning them to observe horizontal, not vertical, movement I can minimize the chance that someone merely rolling over in bed will trigger it. Some experimentation with a sensor pointed at my bed supported this. However, I did notice that the sensor sometimes triggered by movement far off to the side, not directly in front, even without the lens. To fix that, I can set the sensor back into the body of the lamp a bit, so the lamp body blocks IR light from the sides.
The PIR Sensor, with and without lens, and positioned inside the lamp body
One other possible problem became clear in early experimentation: How can a light sensor detect darkness when it's right next to a lamp that's turned on? Without taking some care about positioning, the light from the lamp will cause the sensor to believe it's light, which will keep the light on. All light sensor based lighting controls face this problem, though for most it's inverted.
The answer is to position the sensor so that it receives plenty of ambient light but little from the lamp itself. I decided to put it on top, since the top of the lamp is a solid metal piece. I was a little concerned that the heat might be problematic, but the data sheet for the light sensor says it can operate well above any temperatures the lamp will achieve.
Here's the schematic:
And, while playing with Fritzing, I also created a printed circuit board schematic, designed for an Arduino Mini. I tried hard to arrange things so it would only need a single trace layer, but the trace between R2 (the photocell) and R3 had to cross the 5V line to the PIR so it's in the bottom layer (which is why it's a different color). Also, I jammed things a little tighter than they should normally fit, for example the PIR header block overlaps with the relay and the photocell overlaps both the relay and R3. But that's okay because the photocell and PIR wouldn't actually be mounted on the board. Anyway, here it is:
For $10 I can get that board made by Fritzing Fab. I think I may order it just to experiment with the process and see if I might want to make some custom boards for other things.
I assembled the circuit on Saturday night, with the relay mounted in the base, the PIR in the side and the photocell on top, but the relay didn't work. I think I wired the transistor backwards. I didn't have time to debug and fix it, though, since I work in my bedroom and Kristanne wanted to go to sleep. I guess I need to set up another work area, probably in the basement.
Even if I'd gotten it working, though, it wouldn't have been done, because I was still using the full-sized Arduino Uno board. I ordered a couple of Minis from Sparkfun, to build it for real. The Mini will fit inside the lamp cylinder, opposite the PIR.
After I get it debugged, connected to the Mini and all installed in the lamp, there will still be one piece missing: Power. I need a transformer/rectifier to convert 110 VAC to 5 VDC. I found some circuit diagrams for one of those online, but I think I'll take the easy way out and just hack up a cheap wall USB charger.
All in all, the end result will include some $20 of hardware plus several hours of my time, all to automate a $5 lamp. However, I've learned a lot.
Finally, here's the code. Very simple Arduino code of this sort is normally all in one file, but I separated it to make it easier to write unit tests (which I haven't yet written, but will, and will post in part 2). Here's the untested code.
scent_lamp.h
const int relayPin = 12;
const int motionPin = 13;
const int lightPin = A0;
// Tunable threshold parameters to divide light levels into three categories:
//
// 1. Dark, or night mode. Low enough light that the lamp should be off, except
// for a little while after detecting motion.
//
// 2. Moderate, or hysteresis mode. The lamp should stay in the state it's
// already in. This is mainly to prevent flickering rapidly on and off if
// the light level is right around the dark/light dividing line.
//
// 3. Light, or day mode. High enough light that the lamp should be on.
const int darknessThreshold = 200;
const int lightThreshold = 300;
// Tunable parameter to set the duration the lamp should stay on after
// detecting motion at night, in milliseconds
const unsigned long motionExpirationTimeMillis = 60000L;
bool lampOn;
unsigned long motionExpirationMillis;
bool lampOnPerLightMeasurement(bool currentState);
bool lampOnPerMotionMeasurement();
scent_lamp.ino
#include "scent_lamp.h"
void setup() {
pinMode(relayPin, OUTPUT);
pinMode(motionPin, INPUT);
pinMode(lightPin, INPUT);
lampOn = true;
motionExpirationMillis = millis() + motionExpirationTimeMillis;
}
void loop() {
lampOn = lampOnPerLightMeasurement(lampOn) || lampOnPerMotionMeasurement();
digitalWrite(relayPin, lampOn ? HIGH : LOW);
}
bool lampOnPerLightMeasurement(bool currentState) {
int lightDetected = analogRead(lightPin);
if (lightDetected > lightThreshold) {
return true;
} else if (lightDetected < darkThreshold) {
return false;
} else {
return currentState;
}
}
bool lampOnPerMotionMeasurement() {
unsigned long now = millis();
if (digitalRead(motionPin) == HIGH) {
motionExpirationMillis = now + motionExpirationTimeMillis;
}
return motionExpirationMillis > now;
}
Friday, March 21, 2014
Lighting controls for my bathroom
This is actually my second attempt at an Arduino-controlled lighting control circuit, but the first one included only a photoresistive sensor. This one included a magnetic door closure switch, a PIR motion sensor and a phototransistor. It was actually really easy and worked well, except that I think the PIR I bought may not work, since I could never get it to register any motion at all.
I'll detail the wiring and components below, but first I'll explain what I hope to accomplish with something like this. I'm focused first on designing a self-contained lighting control system for my master bathroom. To do it, I need circuitry that can let my software:
This all worked great (except that I had to simulate the PIR, since it wasn't working).
One other tweak I threw in was to change the behavior when the light sensor detected intermediate light levels. If the bathroom is pitch black, that means it's night time and turning on the lights when the door is open is a bad idea. If the bathroom is very light, there's no need to turn them on at all. In between, it may make sense to turn them on, but there's no need to worry about blasting someone in the bedroom with light because it won't increase the brightness that much. Actually, the ideal way to evaluate that is with an additional light sensor in the bedroom -- which I plan to have, though it will probably be connected to the Arduino in that room, so the central automation controller will have to route that signal.
I altered the logic to include handling of this intermediate light state and it worked very nicely in my testing.
BTW, the idea of routing the light status from the bedroom sensor through the central controller to the bathroom controller is a good example of one thing I want to be careful to achieve: I'm fine with some degraded functionality if the individual room controllers are operating independently, but I think they should have enough local intelligence to operate reasonably well. For example, fairly simple light control logic should work, including honoring light on/off requests from the light switches. Inter-room cooperation is nice, but I don't want to have to cross-connect the rooms directly, so all of that will go through the central controller, which will also enable much more intelligent control, including remote control through web and mobile apps, etc.
Anyway, here are the details:
Here's the schematic, without the PIR:
 And here's the actual breadboarded circuit (with the PIR):
And here's the actual breadboarded circuit (with the PIR):

The relay portion is single-pole, double-throw with 3V coil (needs at least 3V to activate) and can handle up to 10A through the circuit. I used 5V to activate it, with a transistor to switch the coil because the coil draws about 160 mA and the Arduino Uno's data pins can only supply 40 mA. There's also a 220Ω (ish; I think the actual resistor was 270Ω) resistor to limit the current to the transistor base. Pin 12 on the Arduino, configured for OUTPUT, was connected to the resistor and then to the transistor base, so powering that pin switches the relay.
I wired the neutral line of a one-foot extension cord across the normally-open poles of the relay, so activating the relay closes the circuit, then I plugged the extension into the wall and to a desk lamp.

The red wire is 18 AWG solid which, according to the charts I find online, should be good for up to 14A of 120 VAC, so that's safe-ish, though a real circuit should have a 10A fuse. A real circuit should also not leave the relay poles exposed where someone could touch them, and should be soldered or screwed!
The phototransistor's negative side was connected to ground through a resistor, essentially a pull-down, and the positive side connected directly to 5V, and also to the the A0 analog input pin on the Arduino, configured as an INPUT pin. By varying the size of the resistor I could control the amount of light that triggered different input levels on A0. I need to think about what exactly that resistor was doing, electrically -- I'm still not 100% clear on how pulldowns and pullups work.
The magnetic switch is the simplest: One wire is connected to ground and the other to pin 4, configured as INPUT_PULLUP. Putting the magnet by the reed switch (within about 1/2 inch) causes the reed switch to close and the pin to read LOW. Moving it away opens the switch and causes the pin to read HIGH.
The PIR sensor circuit is also trivial to wire: three pins one goes to +5V, one to ground and the last is a data pin which should go HIGH whenever the device sees movement. There is a calibration needed at power up, but that basically consists of waiting 30 seconds before trying to read it. But my data pin never went HIGH. Dunno.
I'll add the code later, since I want to clean it up a little before posting it.
I'll detail the wiring and components below, but first I'll explain what I hope to accomplish with something like this. I'm focused first on designing a self-contained lighting control system for my master bathroom. To do it, I need circuitry that can let my software:
- Tell how much light is present. There's no need to turn on the light if there's enough daylight present. This is for general bathroom lighting; it may make sense to turn additional lights on over the sink for putting on makeup, for example, but I'm assuming that sort of thing will be manual.
- Tell if the "door" is closed. This is both to help with determining if someone is present and to decide when to turn the light on at night.
- Tell if someone is moving in view of the PIR (assuming the PIR works), to help determine if someone is present.
- Turn the light on and off.
This all worked great (except that I had to simulate the PIR, since it wasn't working).
One other tweak I threw in was to change the behavior when the light sensor detected intermediate light levels. If the bathroom is pitch black, that means it's night time and turning on the lights when the door is open is a bad idea. If the bathroom is very light, there's no need to turn them on at all. In between, it may make sense to turn them on, but there's no need to worry about blasting someone in the bedroom with light because it won't increase the brightness that much. Actually, the ideal way to evaluate that is with an additional light sensor in the bedroom -- which I plan to have, though it will probably be connected to the Arduino in that room, so the central automation controller will have to route that signal.
I altered the logic to include handling of this intermediate light state and it worked very nicely in my testing.
BTW, the idea of routing the light status from the bedroom sensor through the central controller to the bathroom controller is a good example of one thing I want to be careful to achieve: I'm fine with some degraded functionality if the individual room controllers are operating independently, but I think they should have enough local intelligence to operate reasonably well. For example, fairly simple light control logic should work, including honoring light on/off requests from the light switches. Inter-room cooperation is nice, but I don't want to have to cross-connect the rooms directly, so all of that will go through the central controller, which will also enable much more intelligent control, including remote control through web and mobile apps, etc.
Anyway, here are the details:
Here's the schematic, without the PIR:
The relay portion is single-pole, double-throw with 3V coil (needs at least 3V to activate) and can handle up to 10A through the circuit. I used 5V to activate it, with a transistor to switch the coil because the coil draws about 160 mA and the Arduino Uno's data pins can only supply 40 mA. There's also a 220Ω (ish; I think the actual resistor was 270Ω) resistor to limit the current to the transistor base. Pin 12 on the Arduino, configured for OUTPUT, was connected to the resistor and then to the transistor base, so powering that pin switches the relay.
I wired the neutral line of a one-foot extension cord across the normally-open poles of the relay, so activating the relay closes the circuit, then I plugged the extension into the wall and to a desk lamp.
The red wire is 18 AWG solid which, according to the charts I find online, should be good for up to 14A of 120 VAC, so that's safe-ish, though a real circuit should have a 10A fuse. A real circuit should also not leave the relay poles exposed where someone could touch them, and should be soldered or screwed!
The phototransistor's negative side was connected to ground through a resistor, essentially a pull-down, and the positive side connected directly to 5V, and also to the the A0 analog input pin on the Arduino, configured as an INPUT pin. By varying the size of the resistor I could control the amount of light that triggered different input levels on A0. I need to think about what exactly that resistor was doing, electrically -- I'm still not 100% clear on how pulldowns and pullups work.
The magnetic switch is the simplest: One wire is connected to ground and the other to pin 4, configured as INPUT_PULLUP. Putting the magnet by the reed switch (within about 1/2 inch) causes the reed switch to close and the pin to read LOW. Moving it away opens the switch and causes the pin to read HIGH.
The PIR sensor circuit is also trivial to wire: three pins one goes to +5V, one to ground and the last is a data pin which should go HIGH whenever the device sees movement. There is a calibration needed at power up, but that basically consists of waiting 30 seconds before trying to read it. But my data pin never went HIGH. Dunno.
I'll add the code later, since I want to clean it up a little before posting it.
Subscribe to:
Comments (Atom)
My collection is complete(ish)!
I drive an electric car, a Tesla Model S. Generally, I never worry about how or where to charge it. It has a large battery and a long range,...

-
 I drive an electric car, a Tesla Model S. Generally, I never worry about how or where to charge it. It has a large battery and a long range,...
I drive an electric car, a Tesla Model S. Generally, I never worry about how or where to charge it. It has a large battery and a long range,... -
 Since I just finished it yesterday, I thought I'd post some photos of my first woodworking project intended to be good enough to go insi...
Since I just finished it yesterday, I thought I'd post some photos of my first woodworking project intended to be good enough to go insi... -
In 2011 Microsoft posted an updated copy of their "Ten Immutable Laws of Security". It's interesting to look at these laws in...